
Automatic Data Generation for SORNet: PROPS Relation Dataset
 Report
Report Dataset Code
Dataset CodeAbstract
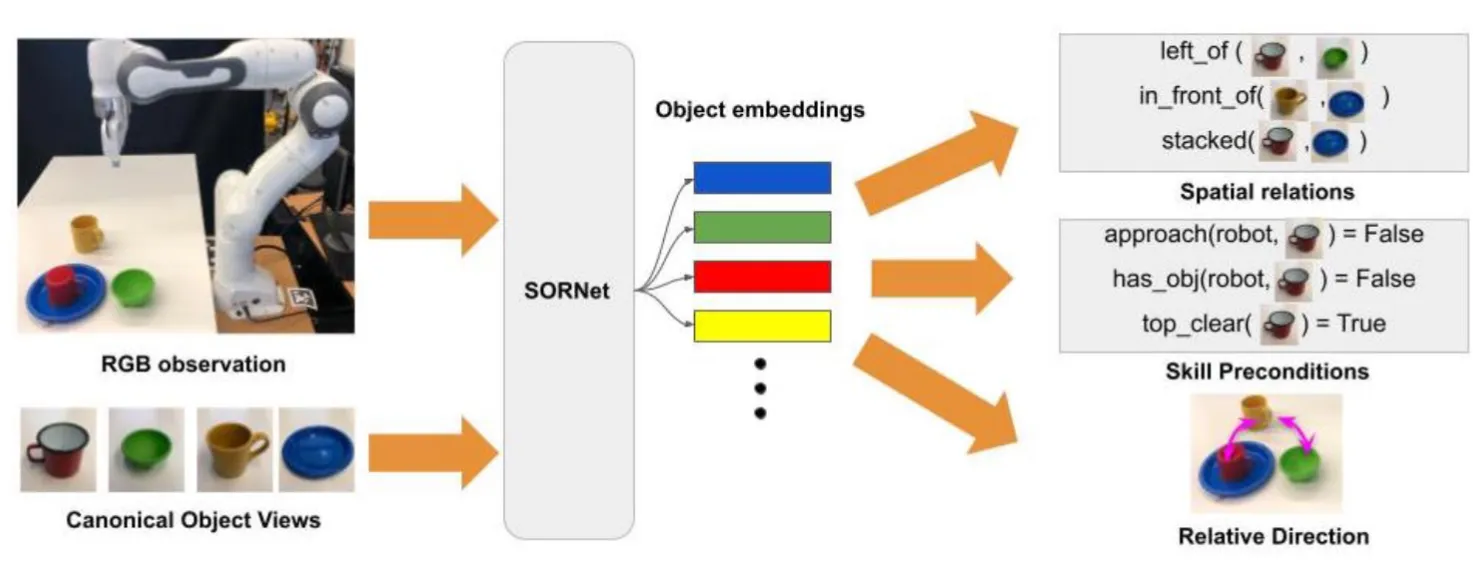
Spatial Object-Centric Representation Network (SORNet, Yuan et al., 2021) is a network architecture that takes an RBG image with several canonical object views and outputs object-centric embeddings. The authors of the original paper trained and tested SORnet on their custom Leonardo and Kitchen data sets, as well as the CLEVR dataset (Compositional Language and Elementary Visual Reasoning). We expanded SORnet’s capability by training it on PROPS Dataset (Progress Robot Object Perception Samples), which was extensively used throughout this course. Training SORNet with PROPS dataset allow us to test its capabilities to a real-world dataset in order to better understand how it performs in real-life applications.
Introduction
There are a plethora of applications for robots that can perform sequential tasks that involve manipulating objects around them. These tasks can range from object assembly to organizing and sorting to packing to much more. However, in order to perform these tasks, robots need a way to recognize the orientation of objects in the world frame and in relation to each other. Having accurate results on the positional relationships between objects in a real-world setting is important in order to perform those tasks. So we tackled applying SORNet to real-world data through training it on the PROPS dataset.
Algorithmic Extension
Our update to SORnet introduces an algorithmic extension designed to boost its performance with real-world data. By developing a base class to compute relations on 3D pose or bounding box datasets, we have made it possible for SORnet to process a diverse range of datasets, including scene images, identifiable objects, and 3D object coordinates. Users only need to overload a few methods to return image and object data, and their dataset will be compatable with SORNet. This enhancement notably streamlines the conversion of data into a format that SORnet can handle.

Results
As an example of our dataset conversion framework, SORNet was trained on the PROPS Pose dataset, with the resulting dataset named the PROPS Relation Dataset. It trained on relations regarding if objects in the dataset are “left”, “right”, “in front of”, or “behind” other objects.
Example Predicate Classifications


Model Performance
With the PROPS Relational dataset, SORNet achieved over 99% total validation accuracy, and over 98% validation accuracy per object, demonstrating the efficacy of our approach. These results are almost identical to that of results on n CLEVR-CoGenT.
| Master Chef Can |
Cracker Box |
Sugar Box |
Tomato Soup Can |
Mustard Bottle |
Tuna Fish Can |
Gelatin Box |
Potted Meat Can |
Mug | Large Marker |
Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Master Chef Can | - | 99.30 | 99.77 | 98.80 | 98.90 | 98.77 | 98.65 | 99.20 | 99.15 | 98.85 | 99.04 |
| Cracker Box | 99.10 | - | 99.37 | 99.80 | 99.20 | 99.39 | 98.54 | 98.70 | 99.55 | 98.30 | 99.11 |
| Sugar Box | 99.20 | 99.14 | - | 99.09 | 99.37 | 98.89 | 99.75 | 99.32 | 99.54 | 99.20 | 99.28 |
| Tomato Soup Can | 98.40 | 99.65 | 99.26 | - | 99.40 | 98.87 | 98.86 | 99.60 | 99.00 | 99.15 | 99.13 |
| Mustard Bottle | 99.30 | 98.90 | 99.26 | 99.90 | - | 98.87 | 99.68 | 98.95 | 98.55 | 98.95 | 99.15 |
| Tuna Fish Can | 98.98 | 99.28 | 99.41 | 98.98 | 97.95 | - | 99.11 | 99.13 | 98.98 | 99.28 | 99.01 |
| Gelatin Box | 99.19 | 99.40 | 99.88 | 99.51 | 99.89 | 99.33 | - | 98.81 | 99.78 | 99.03 | 99.43 |
| Potted Meat Can | 99.20 | 98.70 | 99.03 | 99.75 | 98.30 | 99.38 | 98.81 | - | 98.90 | 98.20 | 98.92 |
| Mug | 98.80 | 99.45 | 99.49 | 98.80 | 98.70 | 98.92 | 99.51 | 99.65 | - | 99.45 | 99.20 |
| Large Marker | 98.30 | 98.10 | 99.43 | 99.20 | 98.95 | 99.23 | 99.24 | 99.20 | 99.55 | - | 99.03 |
| Average | 98.94 | 99.10 | 99.43 | 99.31 | 98.96 | 99.08 | 99.13 | 99.17 | 99.22 | 98.93 | 99.13 |
| Complete Average | 98.99 | 99.10 | 99.36 | 99.22 | 99.06 | 99.04 | 99.28 | 99.05 | 99.21 | 98.98 | |
Training Performance
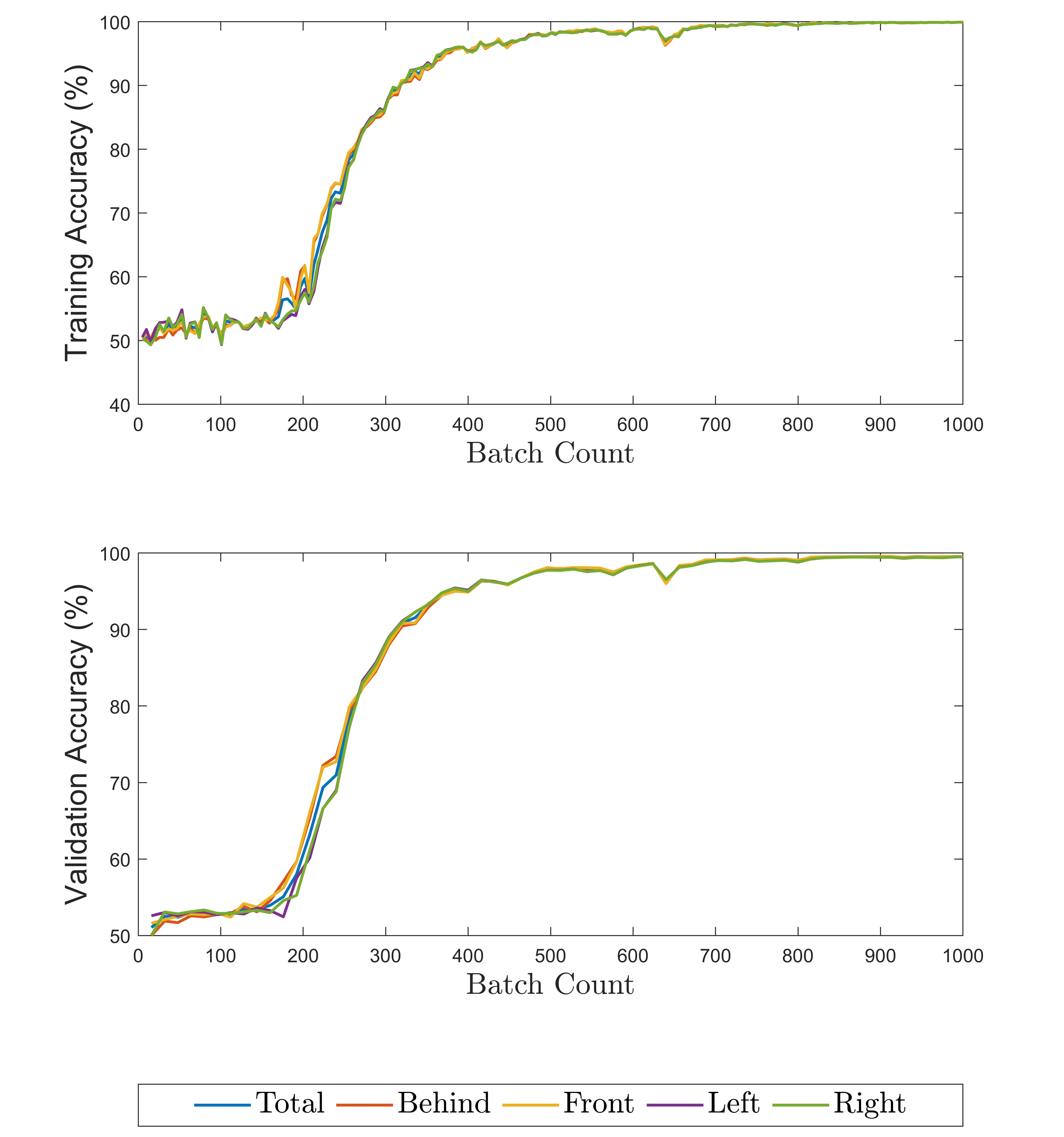
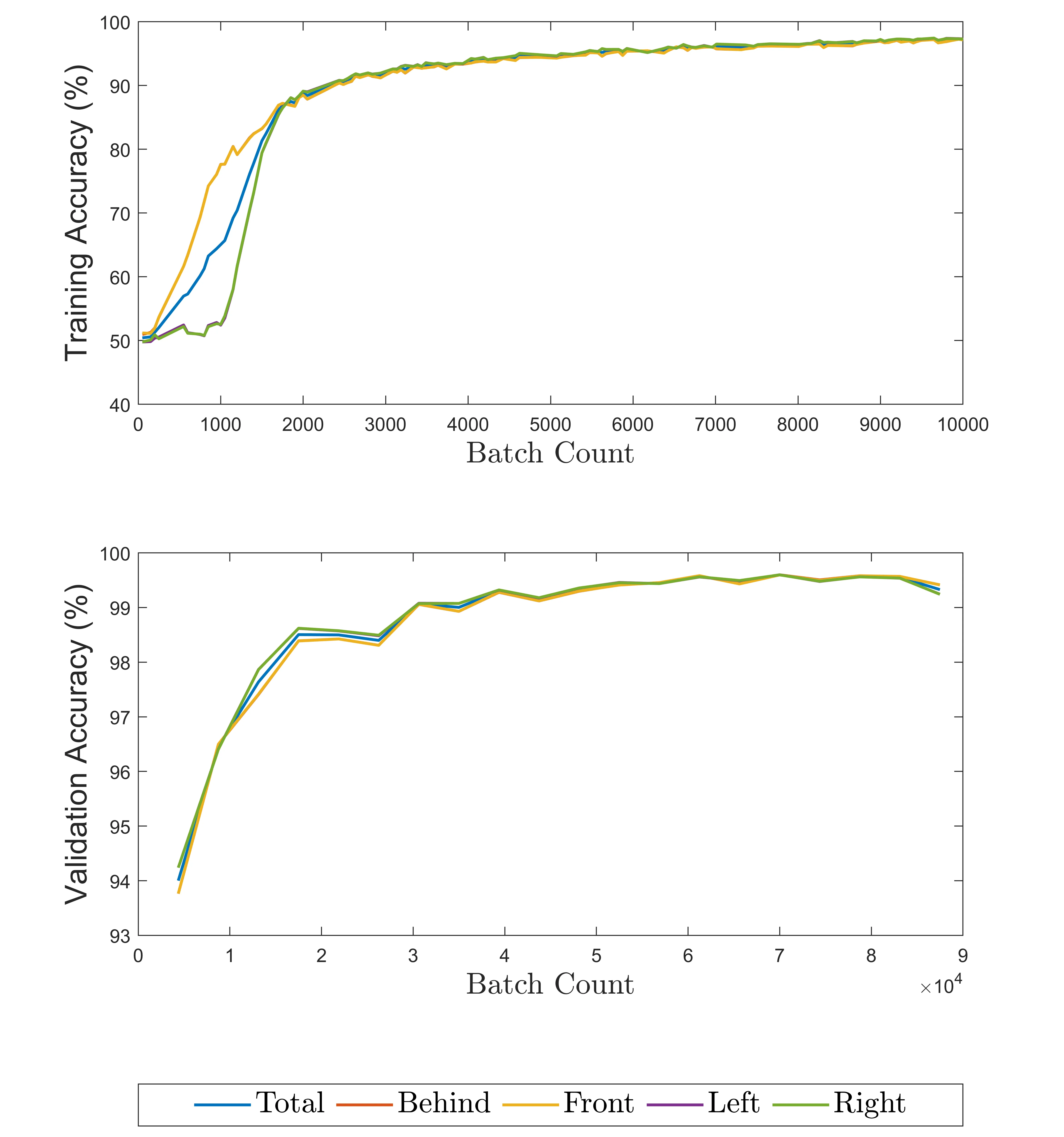
With respect to the training process, the PROPS datset had an initial period of little improvent much longer than CLEVR relative to total training time - the figure below shows only the first 9th of CLEVR training and improves much faster relative to its convergence. We theorize that real world data has more noise, leading to increased time to learn proper object embeddings.
 |
 |
CLEVR Dataset Results |
PROPS Dataset Results |
Other Dataset Use
We highly encourage you to checkout our code and train sornet on your own datasets! Checkout our example usage in our SORNET fork and our example implementaion for the PROPS dataset
To use this framework with another dataset, simply create a new file and overload the BaseRelationDataset class, following the exmaple in PropsRelationDataset. You need to overload each method that raises a “NotImplemented” error in the same manner as which PROPS does. If there is an existing dataset manager class, initialize it in the _init_parent_dataset() method of your derived class to make the implementation easier. Otherwise, load the appropriate file information in each class method and the base class should handle the relation information automatically, provided that the camera frame uses the standard notation.
If you would like to add further relations, simply overload the get_spatial_relations() method, and watch for any locations a “4” was hardcoded for the number of relations.
Citation
If you found our work helpful, consider citing us with the following BibTeX reference:
@article{aldrich2024propsrelation,
title = {Automatic Data Generation for SORNet: PROPS Relation Dataset},
author = {Jace Aldrich, Ariana Verges Alicea, Hannah Ho},
year = {2024}
}
Contact
If you have any questions, feel free to contact Jace Aldrich, Ariana Verges and Hannah Ho.