
Improving Masked Autoencoders by Testing the Viability of Different Features and Adding GAN

 Report
Report Code
CodeAbstract
This project extends the capabilities of masked autoencoders (MAE) based on the research paper “Masked Autoencoders are Scalable Vision Learners”. We aim to enhance MAE in three key areas: data augmentation, masking approaches, and Generative Adversarial Networks (GAN) loss. First, we advanced the current data augmentation techniques to diversify the training data and improve model generalization.This enhances the model’s ability to learn diverse image representations given a more diverse training set. Second, we explore different masking strategies by introducing random and adaptive masking proportions. Unlike fixed masking values used in previous approaches, our method dynamically adjusts masking proportions, either randomly or based on the current training epoch. This dynamic adaptation enables the model to learn more effectively from occluded regions, improving reconstruction quality. Lastly, we integrate GAN loss into the MAE framework. By leveraging GAN’s superior image generation capabilities, we enhance the realism and detail performance of image reconstruction. This addition enables the model to learn from additional high-quality data generated by the GAN, further refining its representations and enhancing overall performance.
Our work
Self-supervised learning is a type of machine learning algorithm where the model attempts to train itself using segments of data compared to human labeling. Self-supervised learning has become more prominent, especially when labeled data is scarce.
In the field of self-supervised learning, masked autoencoders (MAE) have proved to be an effective tool to efficiently learn the intrinsic features of an image, especially when dealing with large-scale image datasets. MAE trains a model by masking portions of an image and reconstructing these masked portions, thus extracting useful representations of the data without the need for explicit labeling. However, although MAE performs well in feature extraction, it still has room for improvement in reconstructing details and maintaining image realism, especially when dealing with datasets with complex visual environments.
In this study, the Progress Robot Object Perception Samples (PROPS) dataset was selected, which is a dataset designed for robot visual recognition tasks and contains images from multiple angles and distances with rich scene variations and complex background information. The characteristics of this data pose additional challenges to the image reconstruction task, especially in terms of maintaining image detail and quality. To address these challenges and to improve the performance of MAE in terms of image reconstruction quality, this study proposes the integration of Generative Adversarial Networks (GAN) into MAE.
The main objective of introducing GAN is to utilize its powerful image generation capabilities to enhance the reconstruction of MAE. In this integrated model, the generator of GAN, also known as the original network framework of MAE, is responsible for reconstructing images to achieve a realistic effect; And the discriminator is dedicated to identifying whether the image is reconstructed or the original image, thus further enhancing the realism and detail performance of the reconstruction through adversarial training. This not only significantly improves the efficiency of robotic vision systems in dealing with complex environments, but also increases their adaptability and accuracy in real-world applications.
Through this study, we hope to show how the combination of MAE and GAN can overcome the limitations faced when using MAE alone and enhance the generalization ability and utility of the model by generating realistic reconstructed images. The experimental design, integration strategy, and experimental results on the PROPS dataset will be presented in detail, aiming to provide new perspectives and approaches to the field of self-supervised learning, especially for applications in robot visual recognition and handling tasks in variable environments.
Results
Improving Existing Methods: This approach used the standard CIFAR10 dataset that was used in the repository provided. This was to measure the accuracy compared to what they already used. This dataset was loaded with the keras datasets library list.
Data Augmentation: Both times we ran the code - with just three additional augmentation techniques and with all five augmentation techniques, generated the same final accuracy of 41.25 percent. This is an improvement over the 40.98 percent accuracy that was achieved with just the standard baseline augmentation techniques.
Adaptive Masking: As shown in figure below, the first randomness method seemed to work effectively as it generated a higher accuracy on the pretraining data. Compared to the previous value of 40.98 percent, this generated an accuracy of 46.52 percent.

Generative Adversarial Networks: After introducing generative adversarial networks into masked autoencoders, this study compared them using the Progress Robot Object Perception Samples dataset. The experimental results show that the weight between the generator and the discriminator loss should be at least 100:1, otherwise it will weaken the effectiveness of the generator. Using 50000 images as the training set and 10000 images as the testing set, experimental results did not show significant differences from the quantity perspective, as shown in Figure below. However, in terms of the effect of reconstructing images, models with GAN loss seem to be better at handling blurry edges.
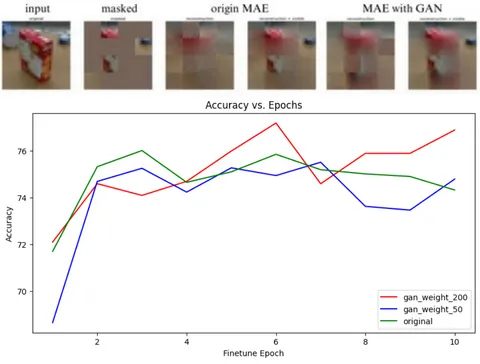
From a quality perspective, we tested using small-scale datasets and found that models with GAN loss were able to extract image features more significantly with fewer data, more extensive masked patches, and fewer pre-training epochs, as shown in Figure above; the reconstruction effect was considerably better than the original models.
Citation
If you found our work helpful, consider citing us with the following BibTeX reference:
@article{MAE2024Rob,
title = {Improving Masked Autoencoders by Testing the Viability of Different Features and Adding GAN},
author = {Jirong Yang, Fangyi Dai and Vaibhav Gurunathan},
year = {2024}
}