
GrapeRob - A Grape Localization Pipeline for Automated Robotic Harvesting

 Report
Report Code
CodeAbstract
Grapes are a globally significant fruit utilized not only for consumption but also for wine production. However, manual grape harvesting faces challenges due to labor shortages and technical intricacies. This paper proposes a robotic grape harvesting system using deep learning based robot perception and 3D reconstruction to compute grape bunch and stem poses for robotic picking. Drawing from previous research in agricultural robotics, this system extends existing methodologies by integrating a novel stem segmentation model into the vision pipeline, and testing on a robotic platform to gauge accuracy. Experiments on the Fetch mobile manipulation shows a grasp success rate of 85.71% and an average gripper pose error of 4 cm on less than 150 training images. Authors can be contacted via email regarding questions, clarifications, and data availability. Below is our methods and results of our experiment.
Initial Paper and Background
The core problem addressed is the need for efficient fruit detection and accurate pose estimation for the furtherment of agricultural robotics. The key idea involves utilizing Mask R-CNN for fruit segmentation and point cloud extraction for pose estimation, and the implementation involves image preprocessing, fruit segmentation, point cloud construction, and pose estimation using a RANSAC cylinder model fitting approach. The evaluation methodology includes metrics such as precision, recall, and intersection over the union (IoU) to evaluate the performance under different lighting conditions. Finally, the paper concludes that the proposed approach achieves high precision and recall rates, an average IoU of about 82%, and a quick inference time of 1.7 seconds, demonstrating its viability for real-world application in grape harvesting robotics.
Overall, the paper presents a noteworthy contribution to the field of agricultural robotics and computer vision in relation to detecting the grape poses, and offers practical solutions to enhance the efficiency and automation of agricultural farming practices. However, there are a few areas for improvement; while the paper effectively addresses the core problem and presents a novel approach, it could benefit from a more in depth evaluation of their methods. Their novel pose estimation pipeline was only evaluated on inference time, not accuracy, and does not test the implementation of such an algorithm on a physical robot - leaving the viability of the pipeline unexamined. Additionally, for a robotic implementation, the pipeline’s detection capabilities are insufficient as a robot needs stem pose in addition to bunch pose for manipulation.
Our Work
In our work, we address these issues in our algorithmic reproduction and extension. We adopted a Mask R-CNN model architecture for both masking branches using the PyTorch and torchvision libraries in order to infer accurate masks for precise localization. The embedded region proposal network uses the extracted feature map calculated by the ResNet FPN to propose RoIs for the mask and box predictors. A mask predictor and box predictor layer was thus added to the RoI Heads for mask and bounding box inference at the end. For testing on the Fetch Mobile Manipulation platform, the depth map directly from Fetch’s infrared sensor was more reliable. Depending on whether the robot should navigate to the bunch or stem, the pipeline will first take the segmentation mask and crop the depth map to the bunch or stem. This provides the per pixel depth of the mask that can be used for 3D reconstruction.
The pose estimation system in the pipeline relies on a well-calibrated camera to estimate the depth map, either through a DepthAnything model or Fetch’s infrared sensor. Depending on the target (bunch or stem), the depth map is cropped, providing per-pixel depth for 3D reconstruction. Each pixel’s depth is transformed into 3D coordinates using the camera matrix. Translation is estimated from the mean of the resulting point cloud, while Principal Component Analysis determines the rotation axis, used with the Rodrigues’ rotation formula to compute the rotational matrix for either cone or cylinder fitting.
A more detailed explanation of the model architecture and process and methods can be found in the paper linked above. In addition, a detailed pipeline of our project can be seen below, as well as illustrated in the gif above.
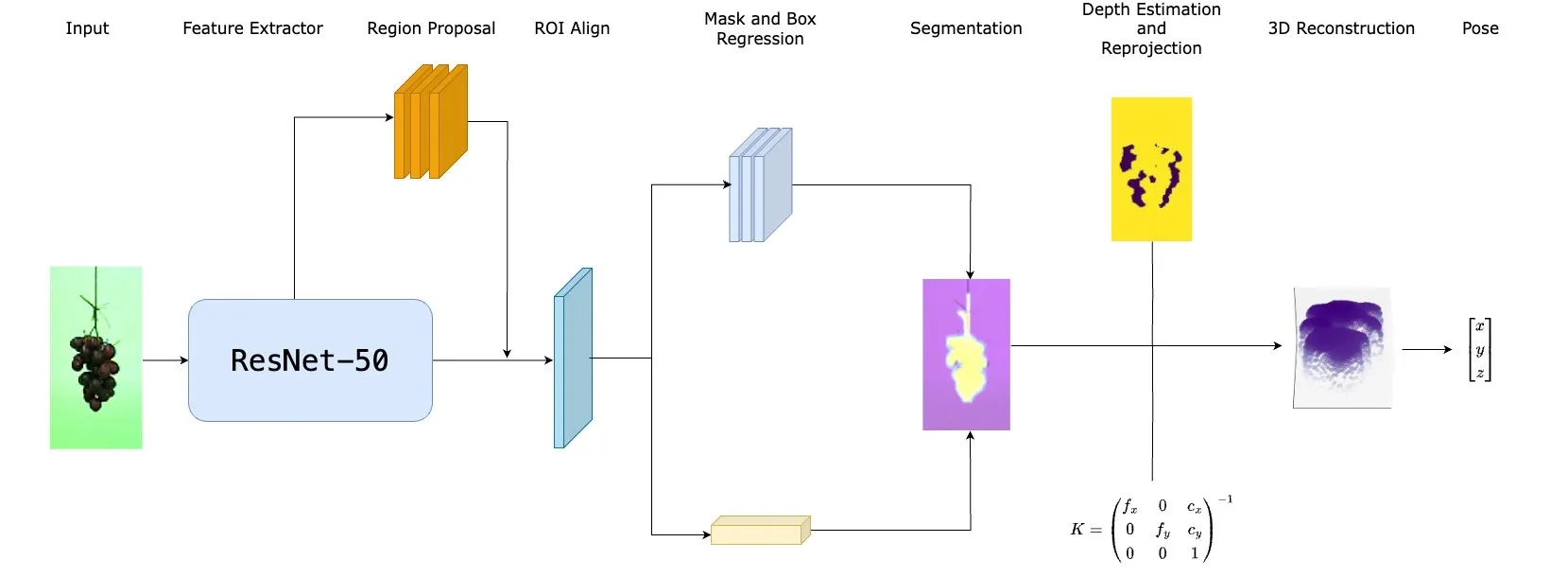
Results
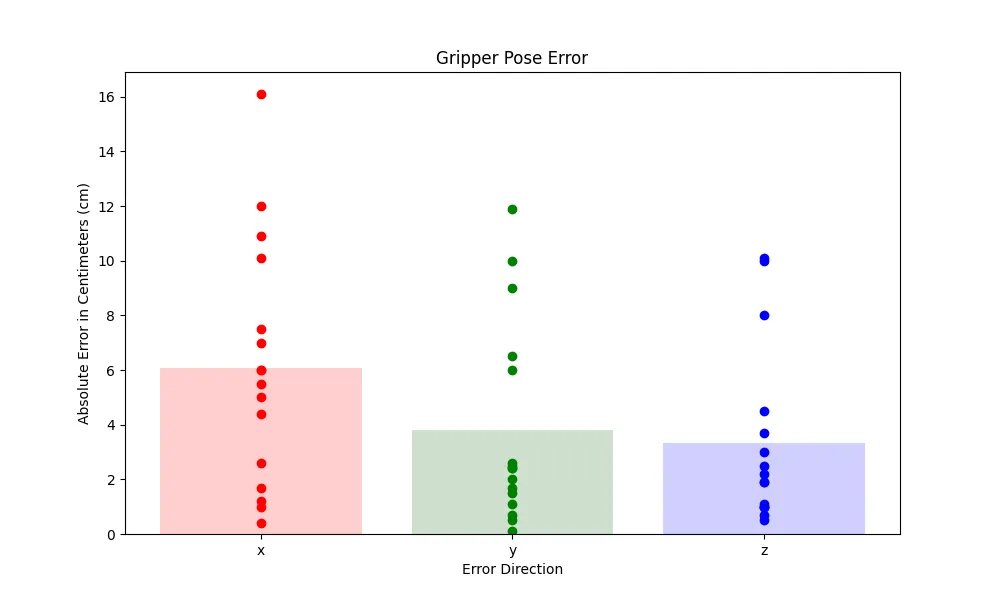
Through experimentation, we found that the grape localization system performs well when implemented on a real robot platform. We had two metrics we tested: the grasp success rate measuring if the robot successfully grasped the grape stem, and the gripper pose error measuring the error between the gripper and the stem location. We tested a variety of black and red grapes, and with 36 successful grasps out of 42 attempts, the Grasp Experiment found a grasp success rate of 85.71% which would satisfy the requirements of a real world robotic harvester. The figure below shows the results of the Gripper Pose Error Experiment, which found an average gripper pose error of 6.08 cm, 3.80 cm, and 3.11 cm in the x, y and z directions respectively. These errors are on the order of hundredths of a meter, indicating that the localization pipeline is performing accurately and the pose outputs are close to the actual location of the grapes.
Project Video and Demonstration
Below you can see a demonstration of the robot successfully graping the grapes, and bringing them back to its side, effectively “harvesting” it! While we have included the front and side views of 1 trial below, we have curated 5 trials into a Youtube playlist, both with the front and side views, and can be accessed below.
Conclusions
Our research was able to expand upon a previous paper, and presents a robust grape localization pipeline tailored for robotic harvesting applications. Addressing the limitations of existing systems, our approach integrates a novel stem segmentation branch into the vision pipeline, enabling precise localization of both grape bunches and their stems. Through experimentation on the Fetch mobile manipulation platform, we demonstrated the performance of our localization pipeline in real-world scenarios. The grasp success rate of 85.71 and a low average gripper pose error of 6.08 cm, 3.80 cm, and 3.11 cm in the x, y, and z directions obtained from our experiments underscores the practical viability of our approach for autonomous harvesting tasks.
In the future we plan to expand the capabilities of the localization system by training the masking model on bunch and stem data from a broader set of environments. This would help the vision model generalize better and output even better mask results. Another key area to expand this study would be to incorporate labeled pose data for the grapes. This could open up the possibility of implementing learning based pose estimation methods. The last area for improvement would be improving runtime by parallelizing the localization pipeline on GPUs. This would drastically reduce pose inference time, and also open the model to being augmented with a probabilistic filter at the end, such as a Kalman Filter. These adjustments would greatly improve the applicability of this system to a real world application.
Citation
Thank you for visiting! If you found our work helpful, consider citing us with the following BibTeX reference:
@article{2024grapeRob,
title = {GrapeRob - A Grape Localization Pipeline for Automated Robotic Harvesting},
author = {Balaji, Advaith and Madhavaram, Isaac},
year = {2024}
}

Contact
If you have any questions, feel free to contact Advaith Balaji and Isaac Madhavaram.