
DeepRob Final Project Report: Classification Mislabeling (ClaM)
 Report
Report Code
CodeAbstract
In this paper, we aim to reproduce and extend the paper Rethinking the Inception Architecture for Computer Vision (Szegedy et al., 2016). This work builds on the Inception architecture of the GoogleNet deep neural network model with the goal of optimizng the network by scaling it up while constraining the increase in computational costs. In this report, our team will reproduce and validate the model on a new dataset, and attempt to extend upon the work by incrementally mislabeling parts of the input data with the goal of reducing bias and limiting overfitting. This study shows that mislabeling increasing proportions of the dataset does not improve overall performance of the Inception-v3 model defined in the original paper as evaluated on the CIFAR-10 dataset by measuring training and validation accuracy over several epochs.
Methods
To reproduce the original paper’s results, we utilized the Tensorflow and Keras python modules to recreate the environment to train the Inception architecture. Due to hardware limitations we had to use the Cifar-10 Dataset, a relatively smaller dataset compared to the massive ImageNet dataset used by the paper. The image below depicts each of the ten labels in the CIFAR-10 dataset with 10 example images per category.

Example photos from CIFAR-10 (Krizhevsky, 2009).
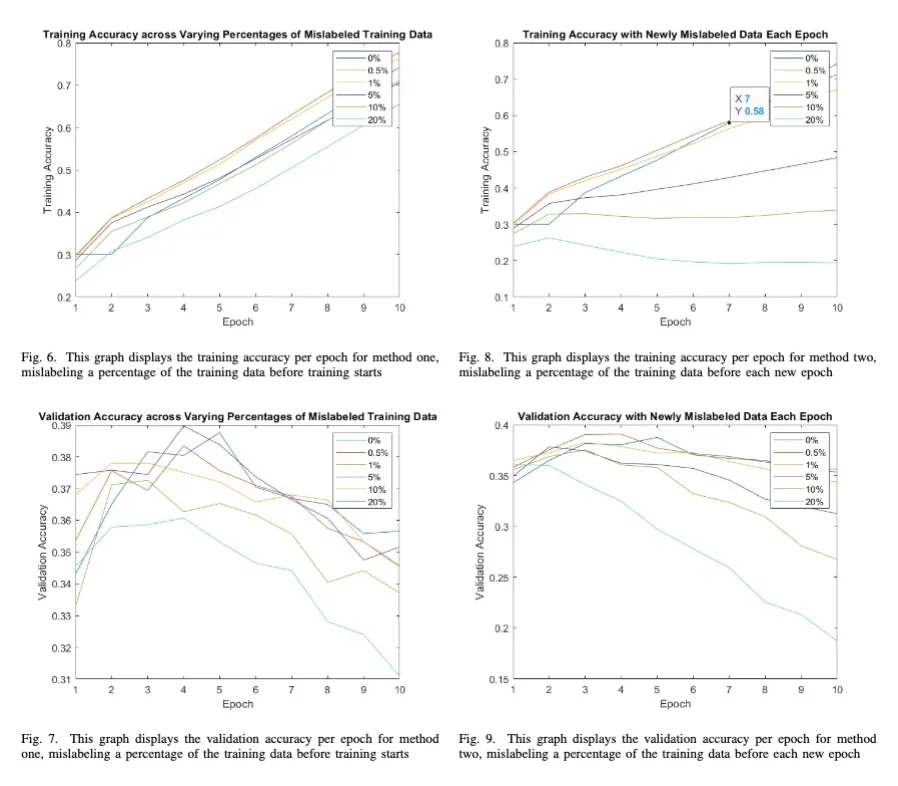
When recreating the paper, it was noticed that while using the CIFAR-10 dataset that the data was being over fitted. At epoch 3 or 4, the validation accuracy would start decreasing, while the training accuracy would continue to increase. In an attempt to combat this over-fitting, and since the inception V3 architecture already has bias included in their model, it was decided to implement a novel form of noise involving randomly mislabeling training data. We implemented this in two distinct ways. The first way that was tested was randomly mislabeling a percentage of the dataset, and then training all 10 epochs on that data with a portion mislabeled. The second way that was tested was randomly mislabeling a percentage of the dataset, and then training one epoch on that data. This mislabeling process was repeated between every epoch so the same percentage of data was mislabeled, but different sets of data was mislabeled each epoch.
Results
We found that classifying a small dataset with inception V3 resulted in over-fitting. Moreover, two different methods of mislabeling data were explored to decrease this over-fitting. it was found that low levels of initial mislabeling of the data increased training accuracy, but both methods did not increase validation accuracy, nor did they decrease over-fitting. In the graphs below, we have plotted the resulting validation and training accuracies over several epochs for each of the two experimental methods described above.
Citation
If you found our work helpful, consider citing us with the following BibTeX reference:
@article{day2024deeprob,
title = {DeepRob Final Project Report: Classification Mislabeling (ClaM)},
author = {Chancellor Day, Zack Vega, Meha Goyal, Tucker Moffat},
year = {2024}
}
Be sure to update this reference to include your team’s author information for correct attribution!
Contact
If you have any questions, feel free to contact Chancellor Day, Zack Vega, Meha Goyal, and Tucker Moffat.