
Choosing how to Grasp the Ungraspable
 Report
Report Code
CodeAbstract
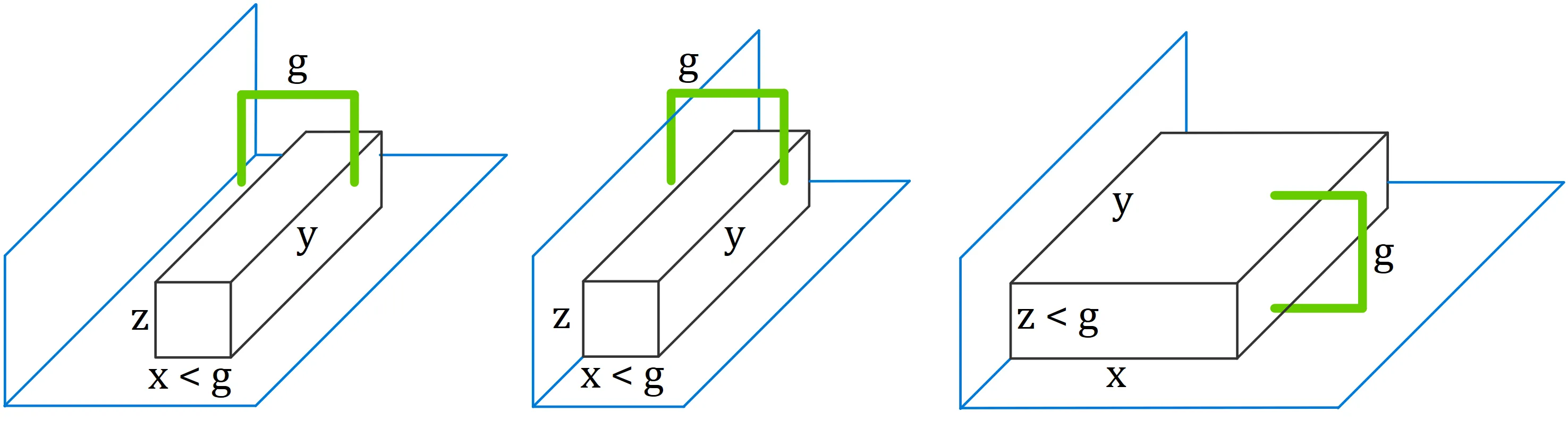
Extrinsic dexterity is the method by which a simple gripper can use its environment to solve complex tasks. In this work, we aim to reproduce and extend the results from Learning to Grasp the Ungraspable with Emergent Extrinsic Dexterity by (Wenxuan Zhou and David Held, 2022). The original paper demonstrates that a simple gripper using intuition about its environment can still perform complex manipulation tasks. That work studies the task of “Occluded Grasping” that aims to reach a grasp in configurations that are initially intersecting with the environment. While the original work only considered occlusions by the ground, our work extends their work by considering occlusions by side walls along with unoccluded configurations. Our system trains different policies for each occlusion type and selects between them at run-time. In simulation, our policy selector was 100% successful at choosing the correct policy for the occlusion type and the policy was then 100% successful at picking up the object. Further work could see how well the trained policies would transfer onto a real robot.
Results
The results of training for different types of occlusions are shown below. The left video replicates the original paper’s results. In each type of occlusion, the robot selects an appropriate policy and executes that policy to pick up the block and reach the target grasp. There are two possible methods of policy selection:
- Simple: The policy selection uses the box’s size. If the box is small enough to be picked up from the top, the bot selects the side occlusion policy. Otherwise, if the block is small enough to be picked up from the side, the bot selects the ground occlusion policy.
- Q-Maximizer: A Q-function in the context of reinforcement learning is a function that takes as arguments a state, action, and goal, and returns the expected reward. The policy selection generates an action based on the current state for each policy, passes that action into the corresponding Q-function, and performs the action that would yield a higher Q-function value. If the ground Q-function yields a higher value than the side Q-function, we choose the action output by the ground policy, and vice versa.
The videos shown below use the Simple policy selector, but comparable results were found with the Q-Maximizer selector.
We found that both policy selectors were 100% effective in simulation, and when the correct policy was selected the simulated robot was able to pick up the block with a 100% success rate. Future work could include transferring ADR-trained policies to a real robot and seeing how they compare.
Citation
If you found our work helpful, consider citing us with the following BibTeX reference:
@article{ungraspable2024deeprob,
title = {Choosing how to Grasp the Ungraspable},
author = {Brown, Jason and Fox, Eli and Harrelson, Jacob and Hippargi, Srushti},
year = {2024}
}
Contact
If you have any questions, feel free to contact any of us.