
Human Aware Motion Planning for 6 DoF Robot Arm in Painting Application
 Report
Report Code
CodeAbstract
Collaborative robots must safely and efficiently operate alongside humans, especially in dynamic and creative environments such as artistic painting. In this work, we develop a human-aware motion planning system for a 6-DoF robot arm collaborating with a human artist. Using real-time 3D human pose estimation from OpenPose combined with depth sensing, we capture the artist’s motion and predict future poses with the lightweight siMLPe network. Predicted human poses are then converted into obstacle representations for real-time collision-aware trajectory planning using MoveIt2. Our system integrates multiple open-source platforms including ROS2, Gazebo, and multiple learning models to enable the robot to adaptively paint around human collaborators. Results show a functional pipeline demonstrating a strong proof-of-concept for human-aware collaboration in creative tasks. Future work includes improving prediction robustness, increasing sensor fidelity, and collecting artist-specific datasets for model refinement. For more in depth information, please check out our technical report linked above.
Background
This project was completed for the Deep Learning for 3D Robot Perception class at the University of Michigan in the winter of 2025. The motion planner developed was an exploration into human-aware planning for a collaborative robot arm for the AURA project in the Robot Studio Lab under Professor Patricia Alves-Oliveira. The AURA project aims to explore what authenticity of the production process of an artwork means, using biometric data, to better understand Generative AI’s impact on the artist community.
System Diagram
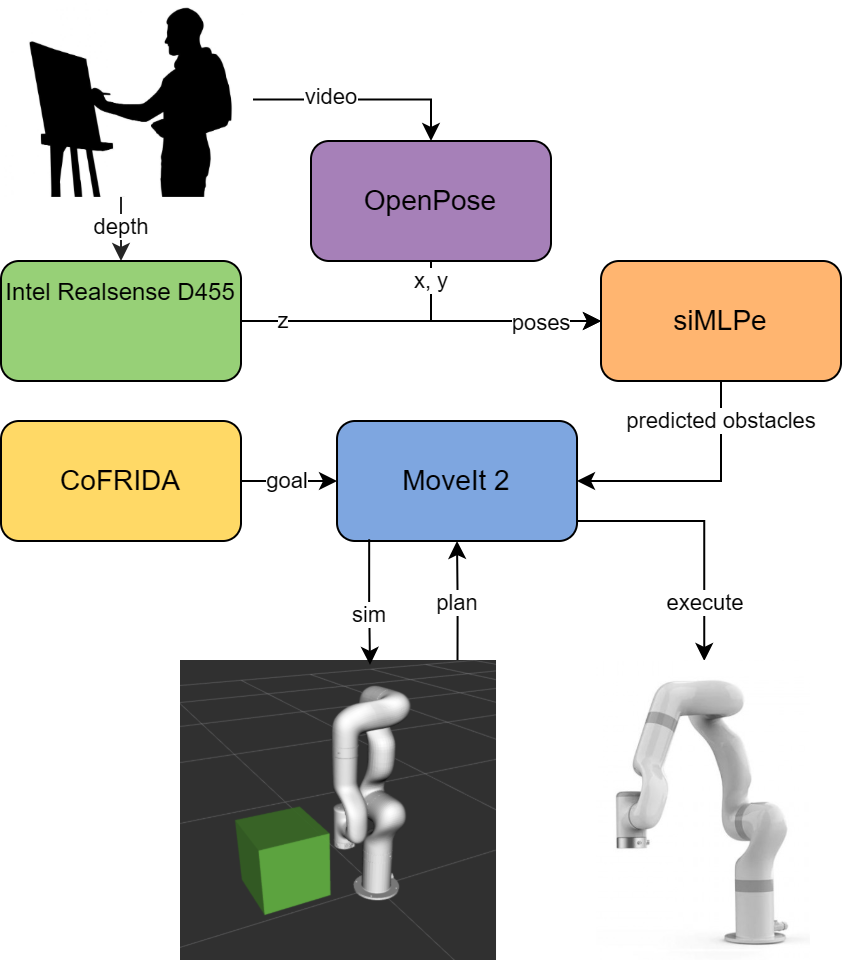
In our system, we are capturing the artists movements using an Intel Realsense D455 camera. Using OpenPose to track the human joint positions and querying the depth data at joint positions, we obtain the human poses in the past 25 timesteps. This is then sent to our pre-trained siMLPe model to predict the poses in the next 10 timesteps. The predicted poses are reduced more as we take the torso and arm joints to create cylinders or other primitive shapes to represent a safe area around the human pose for the robot to plan around. These obstacles are sent to MoveIt which will simulate the obstacles and robot arm to create safe trajectories. The goal positions for the robot are given from the CoFRIDA node, which plans strokes for the robot to paint using Generative AI. Once a trajectory is found, the robot can execute it in the real world.
Challenges
Some of the challenges we ran into were limited hardware, lack of documentation, inconsistent human skeleton formats, and lack of robustness of networks. For the depth camera, we initially tested out the ZED and the PrimeSense depth cameras. The ZED was promising, however it ended up being deprecated and lacked the human tracking SDK capability, so we turned to the Intel Realsense D455 camera. This camera had fewer SDK capabilities, which led us to adding OpenPose in the first place.
A challenge related to the datasets used in training included lack of documentation of H3.6M keypoint joint labels. This made it more difficult to extract the key body parts we wanted to translate into obstacles. Also, it was difficult to format the OpenPose skeleton for the expected siMLPe skeleton structure. OpenPose was formatted with 25 joints, while siMLPe trains on 22 joints but outputs 32 joints. This indirect translation led to uncertainty in the siMLPe output. There was also a lack of robustness to un-detected keypoint joints. When OpenPose does loses tracking, it will return (0, 0) for the 2D location of that joint. Directly sending this data to siMLPe results in inaccurate predictions.
Results
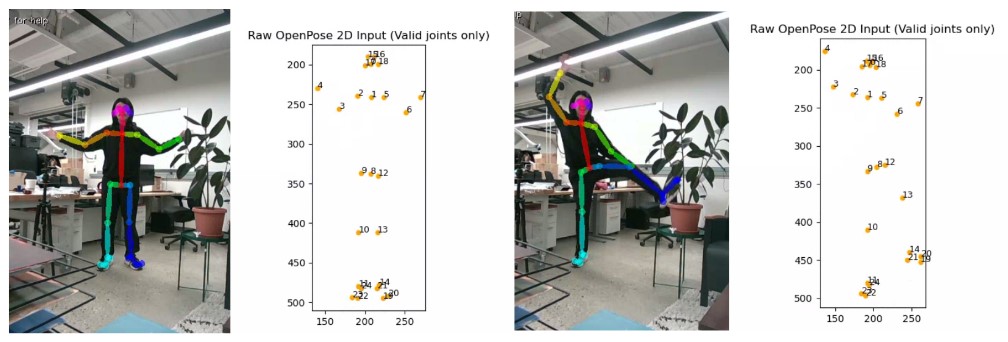
We visualize the detected 2D joint keypoints using OpenPose overlaid on the live RGB camera feed in Figure \ref{fig:openposemap}. The right side of each image shows the extracted skeleton structure in 2D space. This mapping provides the foundation for accurate 3D human pose reconstruction in our pipeline when combined with depth information.
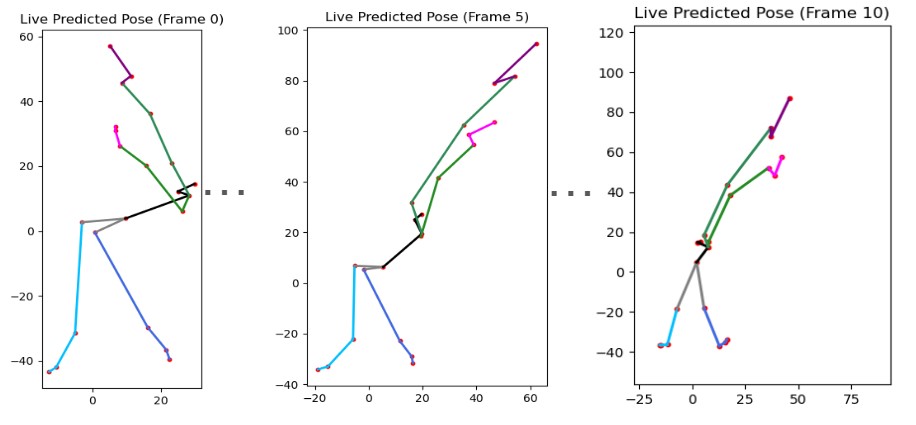
We show the predicted future joint trajectories from the siMLPe network over several frames. Each plot visualizes the progression of joint movements based on past observed poses, demonstrating the model’s ability to anticipate natural human motion with minimal latency.
The predicted human motion from siMLPe were used to generate virtual obstacles around the human body. These obstacles are placed into the motion planning environment in Gazebo, allowing the robot arm to plan and execute collision-free trajectories in real-time alongside a moving human collaborator.
In this work, we showed a strong proof-of-concept for a motion planner using predicted human motion. We were able to apply siMLPe in an online robotic system through the integration and connection of multiple disjoint open-source software.

Future Work
In this work, we assumed that an artist’s movements are not any different from collected data of human movements, such as walking, talking on the phone, or other everyday activities in the 3.6M Human Dataset. Some future work could include creating a dataset of artist movements while painting using motion capture. Modifying siMLPe’s architecture or retraining it for artist motions could also be a way to improve our model for artistic applications. For example, siMLPe does not have any nonlinear activation functions, so attempting to add back some of the complexity of human tracking could improve the model.
Integrating better depth cameras or body tracking modules other than OpenPose could also help our predictions. For measuring the state of a person’s joints, the most ideal setup would be using motion capture, which would definitely be applicable to an artist. While OpenPose provided us with accurate and real-time joint measurements, it sometimes found human skeletons in random objects even when no humans were in frame and was somewhat noisy. Validation of predicted pose data from siMLPe against motion capture would also be an important next step to both improving the model and assuring the results we are getting are accurate.
Improving online obstacle generation would also improve this project. Our current simulated environment runs slowly due to the delay in sending obstacles to Gazebo. This would only decrease in performance if we increased the fidelity of the human, so it would be necessary to improve our performance for the best online results. Also, adding rotation of body links using quaternions from the pose data would greatly improve the motion planning of the robot, as the simulation is more accurate to real life.
Finally, training the network to work even with missing joints or faulty sensor measurements would improve the robustness of the system. To do this, we could record OpenPose data and use it for training siMLPe, as well as change the expected joint input format and number of joints to train on. Retraining the network would likely provide a large increase in accuracy of our predictions, especially since the data is collected using the sensors on our real system.
Acknowledgement
We would like to thank the Deep Rob course and staff for providing us with the knowledge of different deep learning architectures. We also want to thank the Robot Studio Lab for providing us with the resources and project to complete the work.
Citation
If you found our work helpful, consider citing us with the following BibTeX reference:
@article{chen_wu_2025deeprob,
title = {Human Aware Motion Planning for 6 DoF Robot Arm in Painting Application},
author = {Chen, Eric and Wu, Emily},
year = {2025}
}
Contact
If you have any questions, feel free to contact Eric Chen or Emily Wu.