
DOPE-Plus: Enhancements in Feature Extraction and Data Generation for 6D Pose Estimation
 Report
Report Code
CodeAbstract
This study explored enhancements to the Deep Object Pose Estimation framework (DOPE, Tremblay et al., 2018) by improving both its network architecture and synthetic data generation pipeline for 6D object pose estimation. We proposed replacing the original VGG-19-based feature extractor with a Vision Transformer (ViT), aiming to leverage its superior representation capabilities. In parallel, we developed a refined data generation pipeline, resulting in an augmented HOPE dataset (Lin et al., 2021) and a new fully synthetic dataset of a customized object, Block. These datasets were used to train and evaluate our modified DOPE model on two target objects: Cookies and Block. Experimental results demonstrate that incorporating ViT improves pose estimation performance over the original VGG-19 backbone, suggesting the potential for further advancements through the integration of more powerful feature extractors.
Introduction and Backgrounds
As robotics continues to advance, researchers are increasingly exploring ways to equip robots with the capabilities needed to perform everyday tasks. Many of these tasks require fundamental operations such as object fetching, which depend on accurate pose estimation of target objects. This study investigated the DOPE (Deep Object Pose Estimation) proposed by J. Tremblay et al. in 2018, and further extended the feature extraction and data generation pipelines. The original DOPE framework employed VGG-19 as the feature extractor. In our work, we replaced it with a Vision Transformer (ViT), motivated by its superior feature extraction capabilities, particularly in capturing relationships between multiple objects. Meanwhile, we enhanced the original DOPE data synthesis pipeline to augment and generate two new datasets for network training. Our goal is to improve the accuracy of 6D object pose estimation and to validate the effectiveness of our enhancements for object perception in real-world scenarios.
DOPE
DOPE (Deep Object Pose Estimation) is a one-shot, instance-based, deep neural network-based system designed to estimate the 3D poses of known objects in cluttered scenes from a single RGB image, in near real time and without the need for post-alignment.The DOPE network is a convolutional deep neural network that detects objects’ 3D keypoints using multistage architechture.
Firstly, the image features are extracted by the first ten layers of the VGG-19 convolutional neural network (with pre-trained parameters). Then two 3 × 3 convolutional are applied to the features to reduce the feature dimensions from 512 to 128.
Second, these 128-dimensional features are fed into the first stage, which consists of three 3 × 3 × 128 convolutional layers and one 1 × 1 × 512 layer, followed by a 1 × 1 × 9 to produce belief maps and and 1 × 1 × 16 to produce vector fields.
There are 9 believe maps, 8 of them are for the projected vertices of the 3D objects and one for its centroid. Vector fields indicate that the direction from vertices to their corresponding centroids, to construct the bounding boxes of objects after detection.
Data Generation:
As more data is required to train a deep network with high performance, it can be difficult to gather enough data for training. In addition, unlike 2D labeling, making 3D pose labels manually is much more difficult. DOPE proposed a method to generate data, which allows scientists to gather enough number of data rapidly, and greatly alleviate the workload of labeling manually.
The overall data synthesis strategy is to generate two kinds of dataset: “domain randomized (DR)” and “photorealistic (photo)”. The domain randomized data are generated by putting the target object into a virtual environment, which is composed of different distractor objects and a random background. The objects shown in DR images do not necessarily obey physical principles. Photorealistic data are generated by putting target objects into 3D backgrounds with physical constraints. In other words, they are impacted by the effects of gravity and collision.
Algorithmic Extension
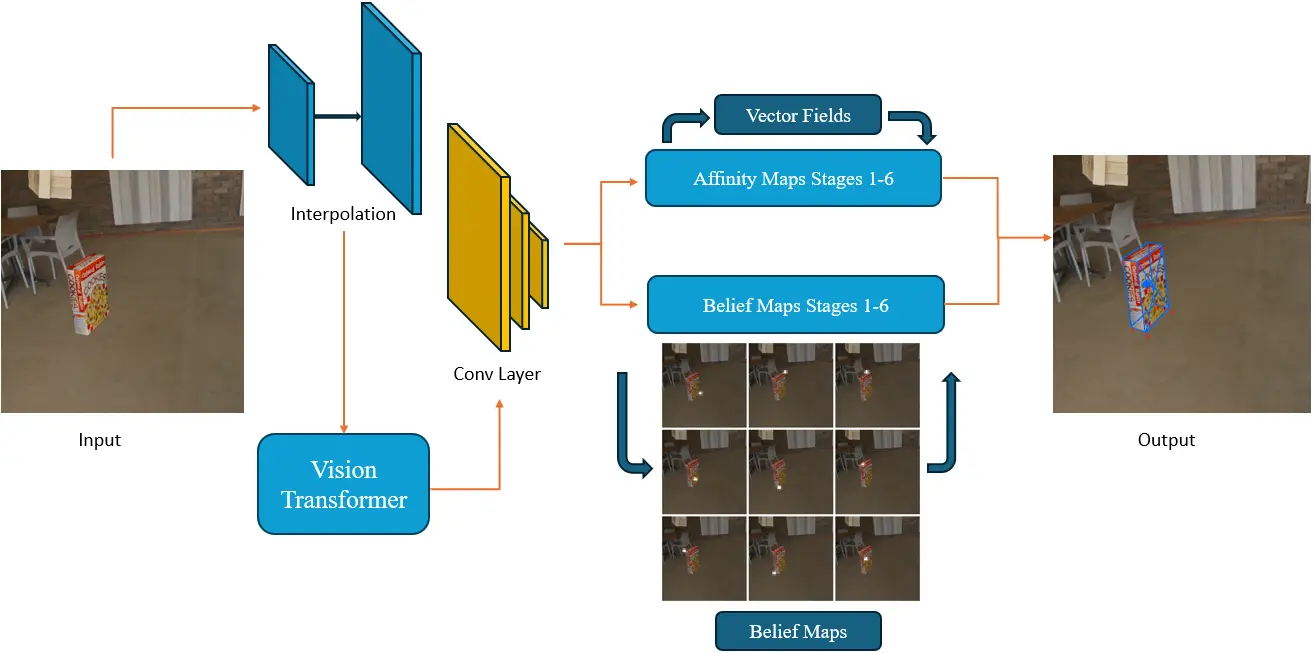
Network Architecture
One of our algorithmic extensions is that we replaced the original VGG19 feature extractor network with ViT, because we perceive ViT’s larger receptive field and its ability to relate the global scene, rather than focus on a local area. To make this change, many parts of the original model backbone need to be modified.We created a pre-trained ViT feature extractor using the timm library. It accepts images of dimension 244 × 244 with a patch size 16 × 16, as a result, interpolating is needed to make sure the input data has a size of 244 × 244. Then we take the output from ViT only in the final layer. At the next stage, two convolutional layers are employed to reduce the number of channel to 128, hence the dimension matches the following network structure (the belief map stages).
Data Generation
We enhanced the original data generation pipeline using BlenderProc to produce two distinct synthetic RGB datasets, each corresponding to a specific target object: Cookies and Block. The Cookies object is part of the publicly available HOPE dataset, while the Block is a newly introduced, custom-designed object. Our pipeline incorporates randomized camera poses, object poses, and 360-degree HDRI backgrounds, while ensuring that these variations remain physically reasonable. These improvements aim to create a more diverse and robust synthetic dataset, helping to mitigate the common sim-to-real domain gap in deep learning applications. The enhanced pipeline consists of four main stages: (1) textured 3D CAD modeling, (2) real-world HDRI background generation, (3) image synthesis, and (4) ground truth annotation pre-processing.
(1)Textured 3D CAD Modeling and Real-World Background Generation
To obtain a precise 3D textured model of the customized object, we first used SolidWorks to create an accurate geometric model with correct dimensions. Blender was then employed to add textures and enrich visual details, including colors and physical material properties, as shown below.
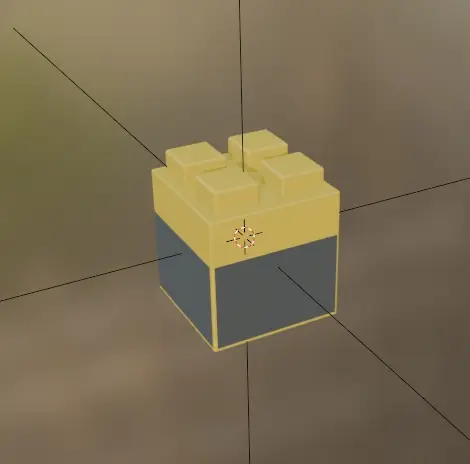
3D Textured Model
For real-world HDRI background generation, we captured raw 360-degree images of the desired physical environments using the Insta360 X3 camera. These images were subsequently pre-processed and converted into HDRI backgrounds using Adobe Photoshop, as illustrated below.

Sampled HDRI Background
(2)Image Synthesis
With all necessary elements prepared, we proceeded to the image synthesis stage. We developed a Python script to randomize the poses of cameras, target objects, and distractors. To emulate typical indoor scenarios encountered in onboard SLAM and manipulation tasks, we assumed that both the camera and the target object remained upright, with randomized yaw angles and small perturbations in pitch and roll. In contrast, distractor objects were randomized with full degrees of freedom as a form of data augmentation, without adhering to physical stability constraints.
(3)Ground Truth Annotation Pre-Processing
With the existing pipeline provided by original paper, ground truth annotations for each frame were automatically generated. However, when constructing a comprehensive dataset for training and validation, it was necessary to combine synthetic and real images from various sources. In this case, the annotation files (e.g., JSON files) often differed in format and configuration. To streamline data preparation and ensure compatibility with downstream tasks, we developed an additional Python script to pre-process and standardize the ground truth annotations.
Innovative Enhanced Datasets
We augmented the original HOPE dataset and created a new dataset for the customized Block object by generating synthetic domain-randomized (DR) images, referred to as HOPE-Syn&Real and the Synthetic Block Dataset, respectively.
(1)HOPE Data Augmentation (HOPE-Syn&Real Dataset)
We generated additional synthetic data based on the HOPE dataset. The original dataset consists of 28 grocery items, with approximately 300 real images per object. We selected Cookies as the target object for subsequent training tasks. To enrich the existing dataset, we synthesized additional 12,000 domain-randomized (DR) images of this object using the enhanced data generation pipeline developed upon, and combined them with the existing real images to form the HOPE-Syn&Real dataset. To verify the quality of the synthesized images, we employed a validation method adapted from the original codebase to visualize the ground truth annotations, as shown below.




Sampled Generated Data and Visualized Ground Truth in the HOPE-Syn&Real Dataset. (Left column: generated RGB images, Right column: visualized ground truths)
(2)Synthetic Block Dataset
In addition to augmenting the HOPE dataset, we created a fully synthetic dataset for our customized Block object using the aforementioned methods and strategies. This dataset consists of over 19,300 domain-randomized images, with random variations in block poses, instance counts, backgrounds, and distractor objects. Furthermore, as shown below, lighting conditions and shadows were simulated and rendered to further enhance realism and dataset diversity.

Synthetic Domain Randomized Image in the Synthetic Block Dataset
Results
To quantify and compare model performance, we trained four models for Cookies and Block in total: one original DOPE and one ViT-DOPE model for each object. The HOPE-Syn&Real Dataset and the Synthetic Block Dataset were used to train Cookies and Block models, respectively. Each used dataset was split into training and validation subsets, where the validation sets contained around 5% - 7% of the total images. Both datasets do not contain photorealistic images due to project deadline constraints and the lack of open-sourced data generation scripts in the original DOPE codebase. Hence, Cookies’ models were trained with DR and real images while Block’s models were merely trained on DR data.
The statistic results of object “Cookies” are shown below:
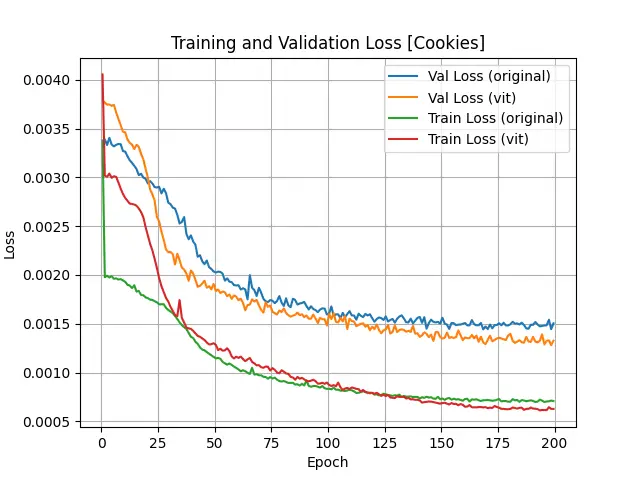
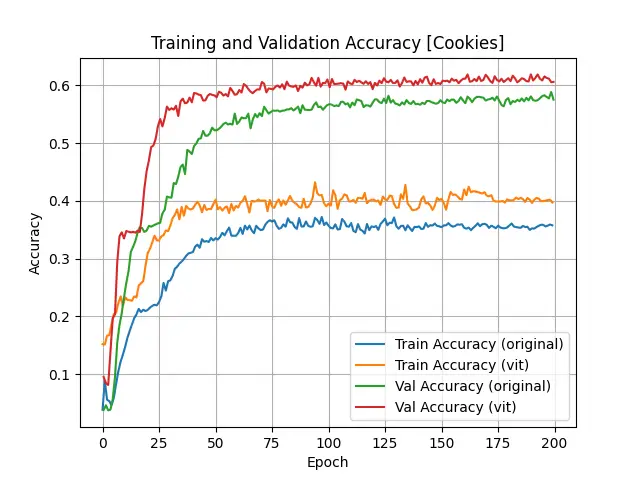
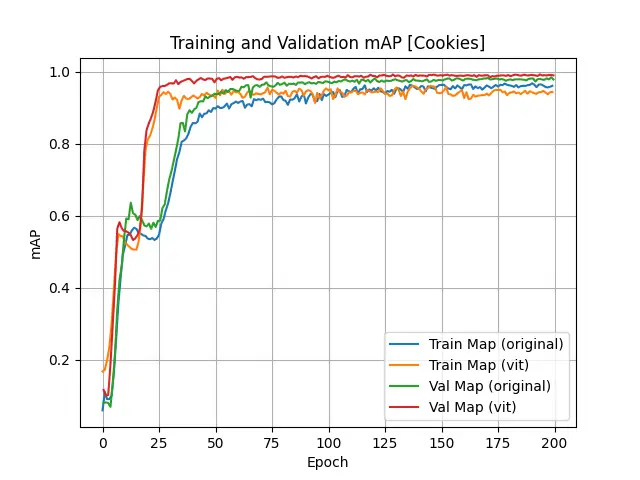
Loss, Accuracy and mAP Values of "Cookies" Object Training
The statistic results of object “Block” are shown below:
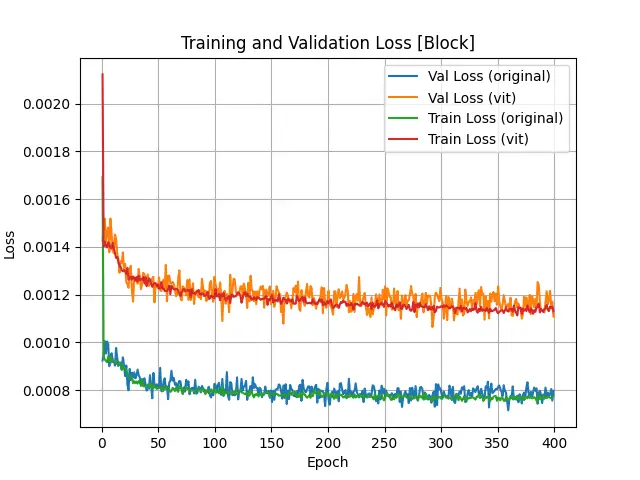
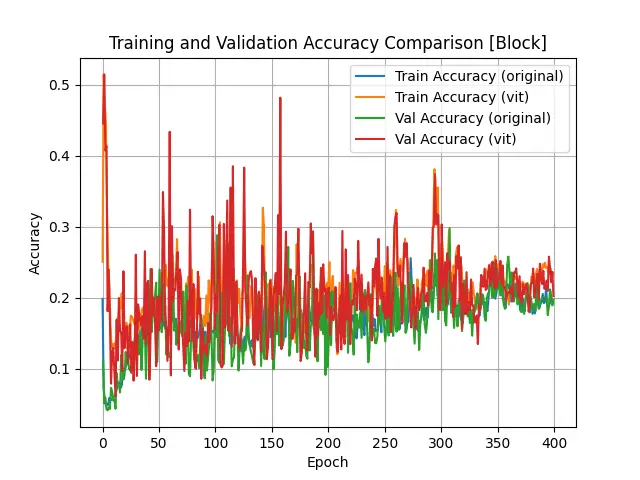
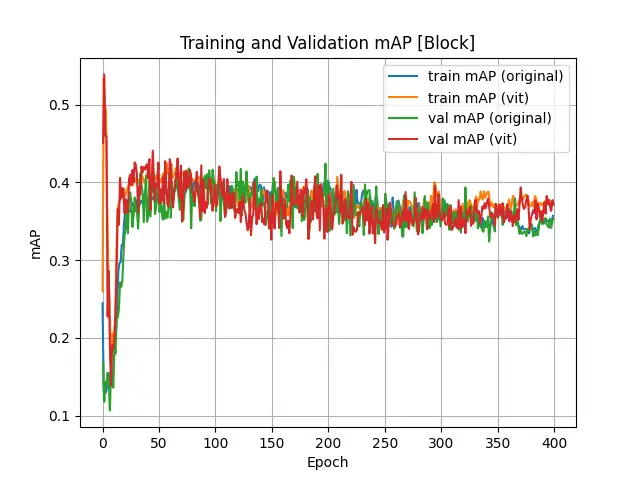
Loss, Accuracy and mAP Values of "Block" Object Training
An example of model belief map prediction is shown below:

Model Inference Example
An example of our model inference to predict the object’s bounding box is shown below:

Model Inference Example
Citation
If you found our work helpful, consider citing us with the following BibTeX reference:
@article{jeffrey2025deeprob,
title = {DOPE-Plus: Enhancements in Feature Extraction and Data Generation for 6D Pose Estimation},
author = {Chen, Jeffrey and Luo, Yuqiao and Yuan, Longzhen},
year = {2025}
}
Contact
If you have any questions, feel free to contact Jeffrey Chen, Yuqiao Luo and Longzhen Yuan.