
Adapting Temporal Ensemble to Flow Matching Policies for Robot Manipulation

 Code
CodeAbstract
In this project, we aim to adapt temporal ensemble inference, which was first proposed by Zhao et al. (2023) for the transformer-based policy ACT (Action Chunking Transformer), to SmolVLA’s flow matching model. We finetune SmolVLA on three robot manipulation tasks: picking up a rigid red block, a semi-deformable makeup sponge, and an irregular, deformable chip wrapper. We collect 50 demonstrations per task using LeRobot’s SO-101 robot arm, and train for 10K training steps each. At inference, overlapping action chunks are blended using exponentially decaying weights, reducing sudden transitions at chunk boundaries. Our results show task-dependent behavior.
Quantitatively, our extension decreases the success rate when manipulating the rigid block, does not change performance when manipulating the sponge, and increases the success rate when manipulating the chip wrapper. Qualitatively, noticeably smoother arm trajectories are observed across all three tasks. We attribute the differences mentioned to the geometry and physical properties of the objects that the robot is manipulating.
Introduction
Robot manipulation has traditionally relied on policies that are task-specific. These robot policies, while accurate on the tasks that they were trained for, struggle to generalize across varying objects and environments. VLAs have recently emerged as a possible and promising approach to this issue. These models combine perception capabilities, an understanding of natural language, and action generation into a single model. They are built on top of massive pretrained vision-language models (VLM), and inherit the ability of VLMs to understand semantic concepts and generalize across varying and unique situations.
The architecture of VLAs make it so that they have a collection of both strengths and weaknesses. One of the biggest strengths that VLAs have is that they can be conditioned on natural language instructions, which allows for a single model to perform a string of tasks without retraining. Their VLM backbone is also the source of another one of their strengths. Because VLMs already have semantic understanding capabilities, the backbone allows VLAs to understand the context of what they’re seeing past just pixel-level information. VLAs are also pretrained on large, diverse datasets, which result in stronger default generalization to unseen objects and scenes compared to traditional behavior cloning methods. Despite that strong generalization, VLAs can still require finetuning on task-specific demonstrations to perform reliably on certain manipulation tasks. On top of that, the quality of the action generation is largely dependent on the demonstration data. Small datasets can often lead to inconsistent or jittery policies. Lastly, VLAs are very expensive computationally during inference due to their transformer-based VLM backbone. These limitations motivate inference improvements that have the ability to enhance policy reliability and smoothness without additional training data.
Algorithmic Extension
Our algorithmic extension involved adapting temporal ensembling from Zhao et al. (2023) and their proposed ACT policy. Temporal ensembling involves keeping overlapping chunks in a buffer and blending them together. Each chunk in that buffer gives a prediction for the current timestep. The blended action is computed as a weighted average across all valid predictions that are stored in the buffer.
ACT is a policy that is deterministic, which means that overlapping chunk predictions for a timestep are closely identical copies of each other that are just shifted. SmolVLA is a flow-matching-based policy that is stochastic, meaning that each chunk prediction is an independent sample taken from the learned action distribution. Because of this, and the fact that each chunk in SmolVLA carries unique information rather than being a shifted repeat, like in ACT, blending across these chunks actually becomes much more meaningful.
This motivated us to adapt temporal ensembling from its original use in a deterministic policy for a stochastic-based framework.
Our team modified the “modeling_smolvla.py” file to maintain an ensemble buffer of recent chunk predictions. A stride parameter was added to control how frequently new chunks are predicted, which balances the smoothness of the trajectory against the computational toll it takes. An exponential decay parameter, lambda, controls the blending process. A lambda closer to 1 gives more equal weighting, while a lambda closer to 0 gives more weight to the newest chunk. The position index into each older chunk is offset by the stride to accurately align the predictions to the current timestep. A safety fallback was added which returns the most recent chunk’s first action in the event that the buffer is empty.

Results
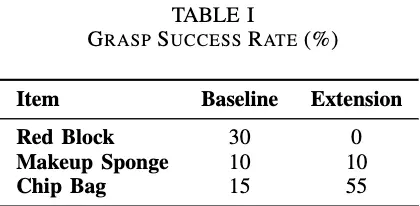
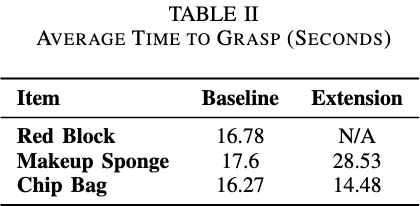
To evaluate the performance of both our baseline and extension, we tested their ability to grasp three different objects within a 30-second period. The three different objects represent different rigidity levels. The items are as follows: a small red block, a light blue makeup sponge, and a Great Lakes empty chip bag. They represent rigid, semi-deformable, and deformable objects, respectively. We recorded three things. Quantitatively, we recorded the success rate (out of 20 trials), as well as the average time to pick up the item, given that it is successful. Qualitatively, we checked to see if the trajectory that the end effector took to the object increased in smoothness.

Quantitative Findings
As seen in Table 1, while the success rate improves when manipulating the empty chip bag with our extension, performance stays the same during sponge manipulation, and completely degrades when attempting to manipulate the rigid, red block.
With our temporal ensemble extension, the success rate for empty chip bag manipulation goes up 40% (15% to 55%), remains the same (at 10%) for sponge manipulation, and decreases from 30% to 0% when attempting to manipulate the red block.
When looking at the average times taken to successfully grasp the objects in Table 2, no definitive trend was observed. The baseline took “longer” to grasp the red block, though that is primarily due to the fact that there was no success data to average the times out for when using our temporal ensemble extension. Our extension took longer to grasp the makeup sponge on average than the baseline, and the time to grasp the empty chip bag was very similar.
Qualitative Findings
Smoother trajectories were noticed when using our temporal ensemble extension. The arm committed to a path much earlier and followed through with that path until the end. With our extension, the end effector consistently got extremely close to the object, and then course-corrected at the very last minute. This is very different from our baseline, in which the end effector corrected itself multiple times while not even halfway to the object. This suggests that our extension generally improved the smoothness of the arm’s trajectory.
Conclusion
Our project shows that temporal ensembling adaptation to flow matching frameworks can improve or worsen manipulation performance based on the object it is trying to grasp.
The manipulation performance on the red block worsened with our extension, as it is a rigid and small object, which requires fast and precise positional corrections. Because we implemented a stride-based ensemble, the policy is not reacting to the most current observation quickly enough. By the time a new chunk has been predicted, the arm might have already overshot or missed the target completely. Position is very important when manipulating rigid objects due to needing to pick them up in a certain way, and so any positional error will result in a failed grasp.
The chip bag, on the other hand, improved due to the fact that it was much larger, irregular, and deformable, meaning that to grasp it, precision is not required. Smooth and consistent gripper closure is much more important than fast corrections for deformable objects. Our extension reduces jitter and smooths out the gripper’s action, which is exactly why a large performance improvement was observed with our extension for chip bag manipulation.
The makeup sponge sort of sits in the middle of both the red block and the chip bag. It’s semi-deformable, similar to the chip bag, but is also small like the red block. We believe this is why performance did not change when manipulating the sponge.
In future work, we would aim to train for more steps (100K - 200K), which would likely improve the baseline performance significantly. Collecting more demonstrations would also be a priority, as it would help the policy generalize better, particularly for the deformable objects. Lastly, task-specific stride selection should be investigated so that actions can be updated more quickly for rigid blocks, while also being able to be adjusted so that smoother and more consistent motion can be prioritized.
We learned that temporal ensemble improves performance on tasks that benefit from a smooth and sustained motion, but is detrimental for tasks that require fast and precise corrections. The stochastic trait of flow matching also makes ensemble blending more meaningful than in deterministic policies, such as ACT.
Citation
If you found our work helpful, consider citing us with the following BibTeX reference:
@article{fonseca2025deeprob,
title = {Adapting Temporal Ensemble to Flow Matching Policies for Robot Manipulation},
author = {Carnino, Yuri, Reddy, Nithin, and Roe, Robert},
year = {2025}
}
Contact
If you have any questions, feel free to contact Yuri Carnino.