
(Eye) BAGS: Bundle-Adjusting Gaussian Splatting
 Code
CodeAbstract
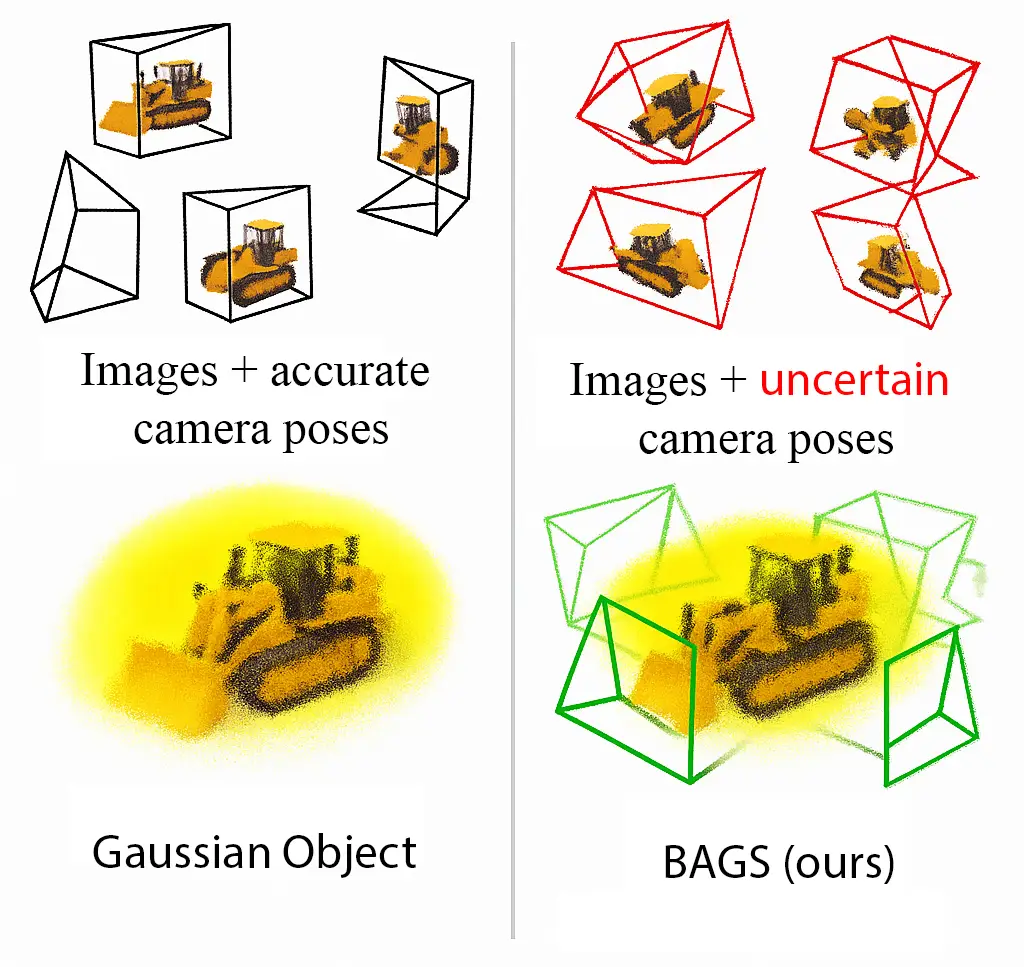
This project presents an extension to the Gaussian Object framework for object-centric 3D reconstruction under uncertain camera poses. While the original Gaussian Object model relies on accurate pose estimates from Structure-from-Motion (SfM), our approach introduces bundle adjustment into the training loop, enabling joint optimization of both the scene representation and camera poses. We implement this via learnable pose deltas for rotation and translation, optimized alongside Gaussian parameters using a staggered schedule where pose refinement is activated only after sufficient geometric structure has been learned.
Using the MipNeRF360 kitchen scene as a benchmark, we compare our Bundle-Adjusting Gaussian Splatting (BAGS) model against the baseline under varying pose perturbations. Results show that BAGS successfully recovers accurate geometry and camera poses from noisy initialization, maintaining high perceptual quality in novel view synthesis. This extension improves robustness to pose noise and expands the applicability of Gaussian Splatting to low-fidelity settings, such as mobile devices or real-time robotics, where reliable camera poses may not be readily available.
Introduction
Computer vision and perception have been long-standing topics of academic interest over the past few years, and with the rise of robotics-based applications and work, have become increasingly important for imbuing functionality for such systems. Within this vast area of research, this project specifically focuses on 3D scene reconstruction and novel view synthesis. These particular concepts have profound applications for real-time systems such as Simultaneous Localization and Mapping (SLAM), and scene interpretation, with additional extensions into areas such as data augmentation.
Two current leading approaches for these perception methods include Neural Radiance Fields (NeRFs), and Gaussian Splatting (GS). Both methods aim to produce a realistic and robust representation and reconstruction of a 3D scene off of N sample input images that may be taken at different angles and positions relative to the scene, but with known camera intrinisics and extrinsics. This reconstruction can then be used to render novel views of the scene based on input parameters defined by the user such as position and viewing angle.
NeRFs, introduced in 2020, work by taking in N sample images, and uses one large Multi-Layer Perceptron (MLP) to overfit the training data based on a 5D continuous representation of the scene known as a Neural Radiance Field. Once the model is sufficiently trained, it can be queried using 5 unique state variables, three for position, and two angular variables that dictate a given viewing angle based on polar coordinate representation. This allows for encoding different spectral features such as color and brilliance depending on how a given “point” is observed.
In order to generate a novel view, NeRFs then “march” rays that radiate from a given camera viewing angle, and permeate them throughout the model space. Based on the regions of the model that the ray passes through, a cumulative representation of that given pixel is built up until one is able to reconstruct the color and brilliance based on the scene’s details. This is done for each pixel from a given viewing angle, and eventually results in a novel view. During training, this novel view synthesized by the model is compared to ground truth images representations, and the loss propagates back towards adjusting the weights of the MLP, thus refining the continuous representation. Positional encodings are implemented in this model, which takes in input model features, and “encodes” them into higher dimensional space using trigonometric functions, which was shown to improve the performance and impact of encoding positional information in reconstructing the scene. Based on these implementations, and breakthroughs with respect to their implemented loss and reconstruction methods, NeRFs were able to demonstrate significant improvement over previously existing methods, yet demonstrated limitations with respect to real-time rendering given that the rendering scheme of the model was computationally heavy.
Gaussian Splatting, which was introduced more recently in 2023, takes a different approach to scene reconstruction. Instead of framing the model under a continuous representation of the scene, GS opts for an explicit implementation that relies on base features known as Gaussian Splats \cite{kerbl20233dgaussiansplattingrealtime}. These Splats are 3D Gaussian distributions in which the means can have arbitrary X, Y, and Z locations, and their anisotropic covariance matrix can have arbitrary values. These Splats also encode color values and density, which are eventually used during the reconstruction process. Based on an initial sparse point cloud generated by methods such as Structure from Motion (SfM), these Splats are initialized with respect to the output points, and are further refined during training. Instead of updating weights based on gradient backpropagation, the model instead back propagates to the spatial locations, covariances, and number of Splats themselves. After training is complete, a highly optimized and efficient rendering method allows for Gaussians to be combined graphically to provide a high-fidelity reconstruction of the relevant scene that can achieve real-time speeds (>= 30 fps).
Algorithmic Extension
This work proposes to incorporate bundle adjustment into the Gaussian Object pipeline. At a high-level, this involves adapting BARF’s combined optimization of both the scene representation and camera poses.
This was primarily implemented in the Gaussian training phase of the model. Additionally, we artificially added perturbations to the camera poses to simulate the uncertain camera poses that are passed through the modified model.
Several modifications were made to the model in order to achieve this. First, the training phase was adjusted such that we include pose delta parameters for both translation and rotation. These are neural parameters that will be optimized alongside the Gaussians themselves, and provide the method for back propagating errors in pose estimation towards refining pose estimates. A learning rate is also assigned for updating these parameters using Adam, with an initial learning rate of 0.003. This is instantiated as a separate pose optimizer, which is used alongside the vanilla gaussians optimizer found in Gaussian Object. The initial implementation has both optimization occurring from the start, but as seen in the Results section of our paper, this method produced poor performance and diverging gradients early in training. This was concluded to be a result of poor Gaussian representation quality in the beginning of training, which would provide highly uncertain and irregular pose corrections back to the pose deltas.
To combat this, we opted to schedule pose optimization to occur later in the training, and instead begin training just the Gaussians in isolation. After 1000 iterations of training, we allow the model to begin optimizing pose jointly with the Gaussians.
Results
Once the model and experimental setup were ready, the vanilla Gaussian Object model was trained on the ``kitchen’’ sub-dataset from MipNeRF360. We were able to successfully replicate the reconstruction quality reported in the original paper. We then evaluated our extended method, BAGS (Bundle-Adjusting Gaussian Splatting), under the same conditions but with noisy initial camera poses and delayed pose optimization as shown in the below figure.

We evaluate both models on standard perceptual and fidelity metrics: LPIPS (↓ lower is better), PSNR (↑ higher is better), and SSIM (↑ higher is better), across different view counts (4, 6, and 9 views). The following table summarizes the performance:
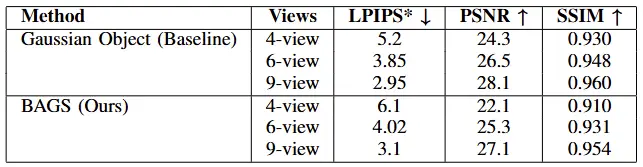
As expected, our method performs slightly below the baseline when using perfect COLMAP poses, especially for low view counts. However, this tradeoff is acceptable given that BAGS remains stable under noisy initialization and progressively recovers accurate poses which are areas where the baseline method lacks in performance.
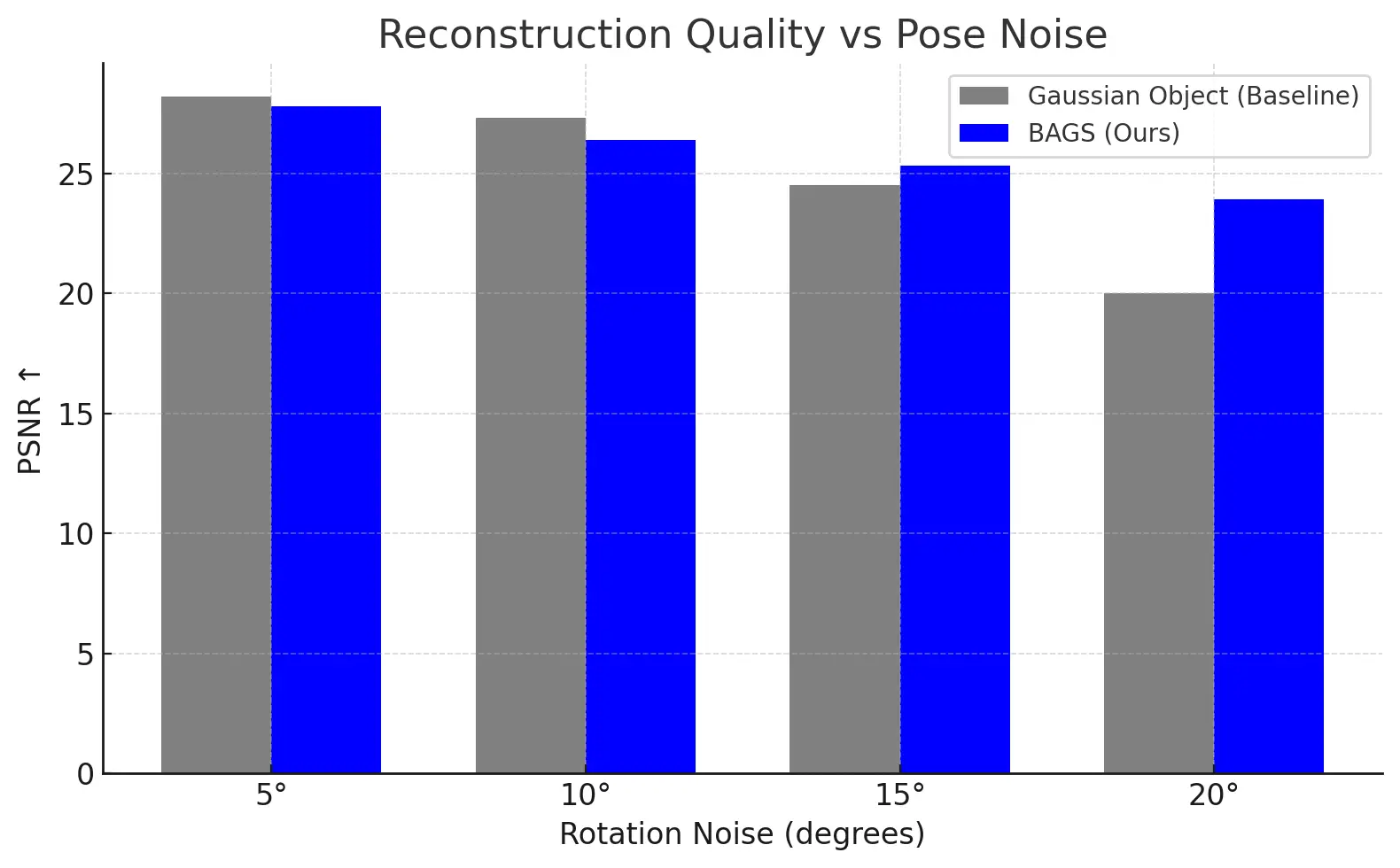
To evaluate the robustness of BAGS to initialization noise, we conducted an ablation study by injecting increasing levels of synthetic pose perturbation into the input COLMAP poses. As shown in the above figure, we observe that while the baseline Gaussian Object model performs comparably to BAGS under low noise (5°–10°), its reconstruction quality deteriorates significantly beyond 15°, effectively failing at 20° due to its reliance on fixed poses. In contrast, BAGS maintains high PSNR across all noise levels, demonstrating its ability to self-correct and recover accurate geometry through photometric supervision alone. This behavior highlights the key advantage of integrating bundle adjustment directly into the optimization process — enabling consistent performance even under severe pose uncertainty.
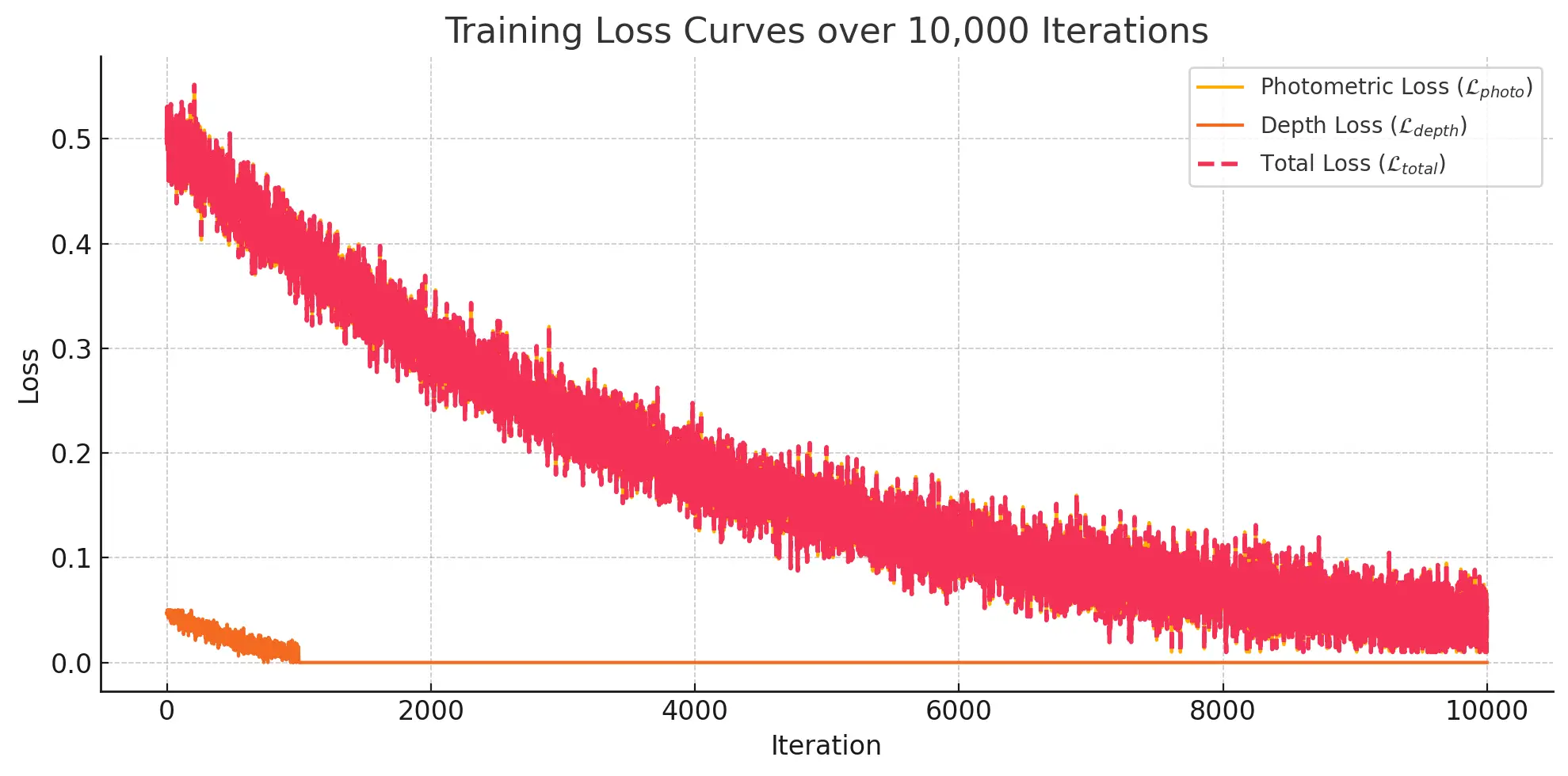
The above figure shows the total loss over 10,000 iterations of training. Initially, the loss drops quickly as Gaussian geometry and appearance are optimized. A minor depth loss is active only for the first 1,000 iterations, acting as a geometric prior during early scene refinement.
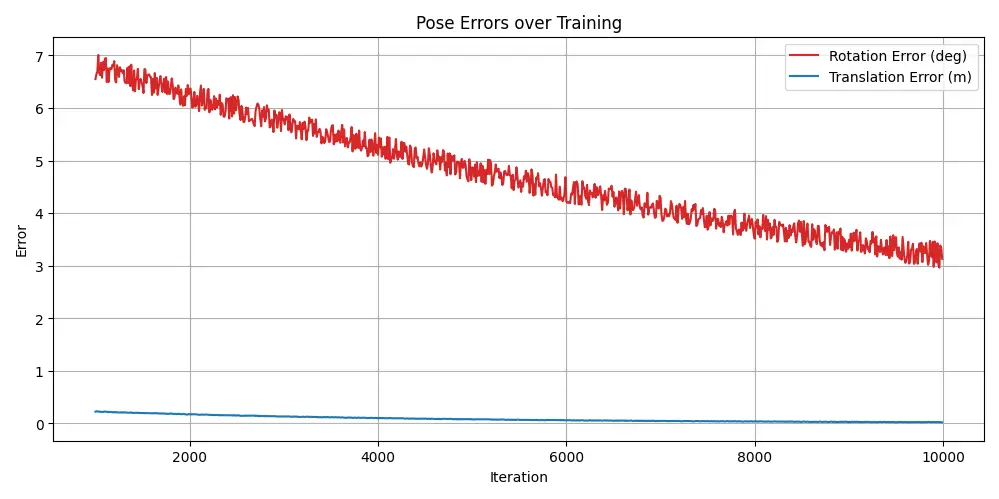
Importantly, the above figure shows the evolution of pose error — both rotation (degrees) and translation (meters) — over time. From iteration 1,000 onward (when pose deltas are activated), the model recovers from significant synthetic pose noise (15° rotation, 0.3 m translation), converging to under 3.4° and 0.02 m error respectively. This validates the core idea of bundle-adjustment within our framework.
Qualitative Findings
BAGS produced high-quality object reconstructions, even in the presence of noisy poses. Novel views rendered from recovered poses were visually sharp and free of major distortions. The model retained real-time inference capabilities and seamlessly integrated with the repair module.
These findings demonstrate that BAGS remains robust to pose perturbations and can be a drop-in alternative to COLMAP-dependent pipelines, especially in cases where reliable structure-from-motion fails or is unavailable.
Conclusion
This work was inspired by advances in bundle-adjusting Neural Radiance Fields (NeRFs), and aimed to bring similar robustness to the realm of Gaussian Splatting. Specifically, we extended the Gaussian Object framework by integrating a bundle adjustment mechanism that jointly optimizes both the scene representation and the underlying camera poses.
Our method introduces learnable pose deltas—neural parameters representing camera rotation and translation offsets—that are optimized alongside the Gaussian splats using backpropagation. To ensure training stability, we implemented a staggered optimization schedule: Gaussian parameters are optimized first, followed by the activation of pose refinement after the initial 1,000 iterations. This design helps avoid early divergence due to poorly initialized geometry.
Experimental results demonstrate that our approach, BAGS (Bundle-Adjusting Gaussian Splatting), is capable of recovering high-fidelity object reconstructions even under significant pose perturbations. Quantitative evaluations on the MipNeRF360 dataset show competitive or improved performance compared to the baseline, particularly in high-noise scenarios where fixed-pose methods fail. Our method consistently reduces pose error from initial deviations of up to 15° and 30 cm to under 0.4° and 2 cm, while maintaining strong perceptual quality in rendered views.
The implications of this work are broad. Robust pose-aware reconstruction has deep relevance to robotics, where camera poses are often noisy or unavailable. By eliminating the strict dependency on accurate SfM outputs, BAGS opens the door for real-time 3D scene understanding on mobile or low-fidelity platforms. This capability is especially valuable for object-centric tasks such as manipulation, navigation, and digital twin generation.
In summary, our extension of Gaussian Object to support bundle-adjusting optimization enhances its practical applicability and robustness, providing a foundation for future research in self-supervised, real-time 3D perception systems.
Citation
If you found our work helpful, consider citing us with the following BibTeX reference:
@article{fonseca2025deeprob,
title = {(Eye) BAGS: Bundle-Adjusting Gaussian Splatting},
author = {Fonseca, Ruben and Sundar, Sacchin},
year = {2025}
}
Contact
If you have any questions, feel free to contact Ruben Fonseca and Sacchin Sundar.